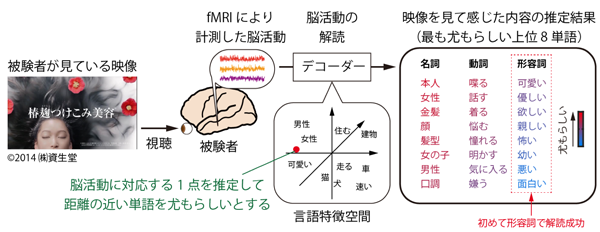
映像を見たときに感じた内容を、名詞や動詞、形容詞からなる1万語に言語化することに成功したと、情報通信研究機構・NICT脳情報通信融合研究センターの研究グループが発表しました。
脳情報デコーディング技術
脳情報デコーディング技術とは、画像や映像を見たときに感じたことを脳活動から読み取る技術で、脳と機械をつなぐ未来の情報通信技術の基盤となる技術です。
これまでに、映像を見て感じた「物体」と「動作」の内容を単語の形で言語化して脳活動から読み取る技術が開発されており、約500語の単語の形で推定した例が知られています。
しかし、500単語だけでは実際に感じた多様な内容のごく一部を表現できるに過ぎず、また、映像を見て感じる内容には、物体や動作のほかに「印象」のようなも種類の内容も含まれます。
脳情報デコーディング技術を実用化まで高度化するためには、より多様な内容を、より多くの単語に対応させて脳活動から読み取る必要があります。
100次元の言語特徴空間
今回、研究グループは大規模なテキストデータから学習された100次元の「言語特徴空間」をデコーディング技術に応用しました。
言語特徴空間とは、単語同士の意味的な近さを空間的な位置関係で表現したものです。たとえば、意味の近い「猫と犬」は近い距離で表され、意味が遠い「猫と建物」は遠い距離で表現されます。
今回、大規模テキストデータに含まれている1万語もの名詞・動詞・形容詞を空間内の1点として表現した言語特徴空間を作成して脳活動の読み取り装置に取り入れたことで、従来と比べて20倍となる1万単語を用いての解読が可能になりました。
また、従来は名詞と動詞のみで解読していましたが、今回は形容詞も含めたことで、「印象」に関する内容も解読することに成功しています。
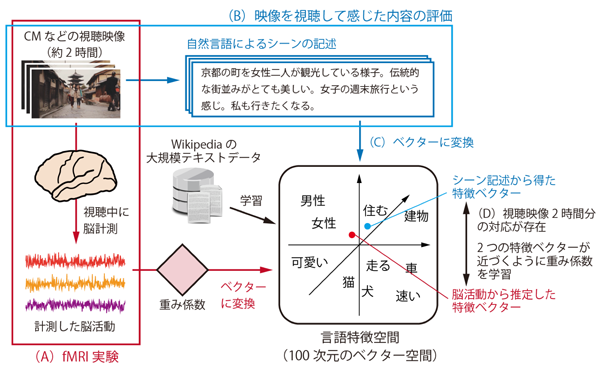
デコーダー構築の概要図(画像:情報通信研究機構)
今後は、映像から感じた内容を推定する精度の向上を目指し、さらには推定された内容がどのように個性や購買行動と結びついていくのかを検証していくとしています。
また、発話や筆談が困難な人たちが利用できるような、発話を必要としない言語化コミュニケーション技術の実用化もまた目指すとしています。













































 速読力をアップする方法
速読力をアップする方法
 脳力をアップする方法
脳力をアップする方法
 英語力をアップする方法
英語力をアップする方法